En simulation de flux, tout repose sur le modèle. La simulation elle-même, -c’est-à-dire lorsqu’on démarre l’expérience- ce sont le logiciel et l’ordinateur qui s’en chargent. Mais le modèle, c’est vous et moi qui le faisons. S’il est complètement faux, la simulation se déroulera aussi bien qu’avec une représentation fiable –les résultats seront erronés, c’est tout.
Le modèle peut aussi être relativement correct, dans le sens où il est fidèle au système représenté, mais chargé de quelques défauts qui vont le rendre difficile à utiliser ou à faire évoluer, une sorte de bombe à retardement qui fera des dégâts si on touche là où il ne faut pas.
Modéliser, cela s’apprend : en connaissant bien le logiciel utilisé, en "traduisant" d’emblée le parcours d’une pièce dans un atelier en une séquence d’opérations et de règles, en ayant déjà fait d’autres modèles semblables… Comme dans tous les métiers, l’expérience compte beaucoup.
Le modèle parfait n’existe pas, bien entendu – partageons cependant quelques principes utiles pour tendre vers cet idéal.
Des objectifs précis
L’étude de simulation de flux doit avoir pour but de répondre à certaines questions, qu’il faut avoir explicitées et quantifiées. Pas de périmètre vague, d’indicateurs imprécis, d’objectif général et flou. Souvent certains choix de modélisation dépendent directement des objectifs de l’étude. Et s’il y a de nombreuses questions de niveau différent, on fera plus d’un modèle.
L’indépendance des données
Le modèle doit n’être que structure et logique, et pouvoir se construire en ne s’appuyant sur aucun chiffre. Sa vérité restera vraie que l’opération dure douze secondes ou douze heures ou un certain temps. Il digérera le plan de production d’hier, d’aujourd’hui et de demain.
Les données seront importées en début de simulation, ou puisées dans une base de données interne : n’allez pas cacher un temps gamme dans les paramètres d’une machine, ou pire encore écrire une référence produit dans le code d’une logique d’orientation des pièces ! Modèle et données sont indépendants.
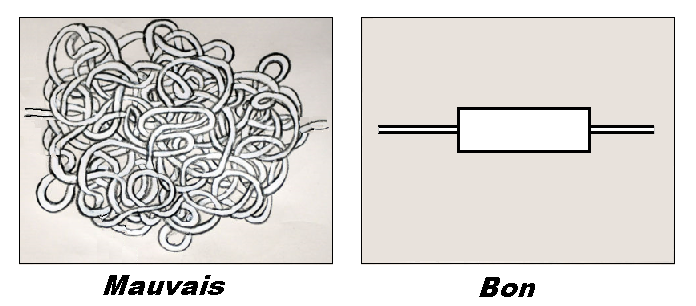
Une taille limitée
Un modèle un peu svelte, c’est toujours mieux : on le comprend plus rapidement, il tourne plus vite, on le maintient plus aisément. Vous avez justement une très grosse usine à simuler, avec plein de détails à prendre en compte ? Il faut être sobre quand même. Le gros modèle trahit la problématique mal définie, les détails sans enjeu modélisés pour se faire plaisir, la réflexion préalable qui n’a pas été menée jusqu’au dépouillement des besoins réels. Deux modèles concis valent beaucoup plus qu’un gros modèle.
Une base de données structurée
Il faut vraiment prendre le temps d’organiser les données du modèle en tables relationnelles (quand on dispose de ces outils), en confirmant les liens entre les différentes catégories de données. Ecrire la structure de la base de données, voire les emplacements de lecture et d’écriture dans le modèle, fait partie des premières étapes de la modélisation.
L’interface utilisateur a priori
Qui utilisera le modèle ? Là aussi bien des choix dépendent du profil de l’utilisateur, du temps qu’il consacrera aux simulations. Il faut échanger avec lui pour comprendre non seulement quels indicateurs il souhaite, mais sous quelle forme ; pour prévoir quelles tables de données (cf. point précédent) serviront à ses hypothèses, et quelles autres lui seront interdites. Ajouter l’interface utilisateur une fois le modèle « brut » terminé est possible, mais cela se fait rarement sans défaire pour refaire autrement certaines portions.
Anticiper sur l’évolutivité
Certains modèles ne servent que pour une étude, mais d’autres évoluent sur des années, ressuscitent alors qu’on les croyait devenus inutiles. Pour ceux dont la modélisation est le métier, il faut penser à l’avenir, c’est-à-dire documenter, expliciter, commenter partout où c’est possible. La modélisation n’est qu'une forme originale de la programmation, et doit en avoir le même savoir-vivre et la même rigueur.
Bon travail !